Raft共识协议
Raft⌗
3个子问题⌗
- 选主
- 日志复制
- 安全
3种角色⌗
- follower
- candidate
- leader
状态转换图⌗

3种RPC⌗
- VoteRequest
- AppendEntries
- InstallSnapshot
Leader选举⌗
Follower –> Candidate⌗
Follower没收到心跳的时间 > Heartbeat Timeout
Candidate –> Candidate (选举超时)⌗
处于 Candidate 状态的时间 > Election Timeout
Candidate(选举)⌗
先建个term并投票给自己
Candidate 向其它节点 node发投票请求
Candidate.term小于 node. term,失败并降级为Follower
Candidate.term大于 node. term,成功如果node也是Candidate则降级,并更新term
Candidate.term等于node. term,如果node也是Candidate失败,否则4
比较上一条日志的term,如果node大则失败,小则成功 ,等于到5
比较上一条日志的index,如果node大则失败,否则成功
Candidate –> Follower⌗
Candidate选举时,发现其它节点term > 自己term.
Candidate –> Leader⌗
Candidate选举结果 > 总节点数/2
获取Leader结点特性
1. 有最大的Term;
2. 如果Term相同,则有最大的Index;
3. 如果Term相同,Index也相同,就看谁最先发起;
4. 日志要求,日志中包含所有已提交的日志条目。重要!
日志要求:Candidate必须联系集群的大多数才能被选举,这意味着每个提交的条目都必须存在于其中至少一台服务器中。如果Candidate的日志至少与该多数服务器日志中的日志一样最新(以下精确定义了最新),则它将保存所有已提交的条目。 Raft通过比较日志中最后一个条目的索引和任期来确定两个日志中哪个是最新的。如果日志中的最后一个条目具有不同的任期,则带有较新任期的日志是最新的。如果日志以相同的任期结尾,则以索引更大的日志为准。为了避免以下情况:
Leader(维持)⌗
向所有结点发送心跳和日志
Leader –> Follower⌗
发现其它节点term > 自己term.
日志复制⌗
- 客户端的向服务端发送请求(指令)。
- follower接收到请求转发给leader
- leader 把这个指令作为一条新的日志条目添加到日志中,然后并行发起 RPC 给其他的服务器,让他们复制这条信息。
- 假如这条日志被安全的复制 > 总结点/2,leader就提交这条日志并返回给客户端。
- 关于日志复制异常的Follower,Raft异步会通过强制 follower 直接复制 leader 的日志解决
日志冲突及解决⌗
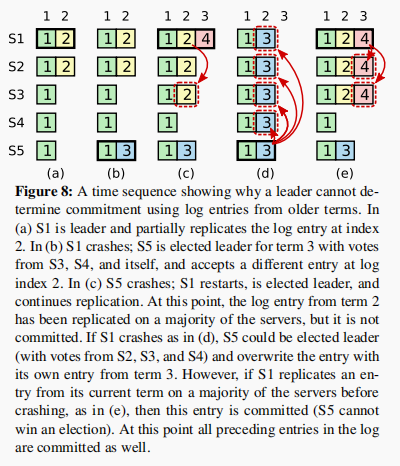
Leader不会主动提交前面任期的日志。而是通过提交当前任期的日志,而间接地提交前面任期的日志。
Raft never commits log entries from previous terms by counting replicas. Only log entries from the leader’s current term are committed by counting replicas; once an entry from the current term has been committed in this way, then all prior entries are committed indirectly because of the Log Matching Property.
Prevote⌗
Follower在electionTimeout没收到心跳之后,会发起选举,并转为Candidate。每次发起选举时,会把Term加一。由于网络隔离,它既不会被选成Leader,也不会收到Leader的消息,而是会一直不断地发起选举,Term会不断增大。
一段时间之后,这个节点的Term会非常大。在网络恢复之后,这个节点会把它的Term传播到集群的其他节点,导致其他节点更新自己的term,变为Follower。然后触发重新选主,但这个旧的Follower节点由于其日志不是最新,并不会成为Leader。整个集群被这个网络隔离过的旧节点扰乱,显然需要避免的。
在PreVote算法中,Candidate首先要确认自己能赢得集群中大多数节点的投票,这样才会把自己的term增加,然后发起真正的投票。其他投票节点同意发起选举的条件是(同时满足下面两个条件):
- 没有收到有效领导的心跳,至少有一次选举超时。
- Candidate的日志足够新(Term更大,或者Term相同raft index更大)。
PreVote算法解决了网络分区节点在重新加入时,会中断集群的问题。在PreVote算法中,网络分区节点由于无法获得大部分节点的许可,因此无法增加其Term。然后当它重新加入集群时,它仍然无法递增其Term,因为其他服务器将一直收到来自Leader节点的定期心跳信息。一旦该服务器从领导者接收到心跳,它将返回到Follower状态,Term和Leader一致。
日志压缩⌗
在实际的系统中,不能让日志无限增长,否则系统重启时需要花很长的时间进行回放,从而影响可用性。Raft采用对整个系统进行snapshot来解决,snapshot之前的日志都可以丢弃。
成员变更⌗
集群配额从 3 台机器变成了 5 台,可能存在这样的一个时间点,两个不同的领导者在同一个任期里都可以被选举成功(双主问题),一个是通过旧的配置,一个通过新的配置。
解决方法⌗
Raft解决方法是每次成员变更只允许增加或删除一个成员(如果要变更多个成员,连续变更多次)。
复制状态机⌗
一致性算法是从复制状态机的背景下提出的(参考英文原文引用37)。在这种方法中,一组服务器上的状态机产生相同状态的副本,并且在一些机器宕掉的情况下也可以继续运行。复制状态机在分布式系统中被用于解决很多容错的问题。例如,大规模的系统中通常都有一个集群领导者,像 GFS、HDFS 和 RAMCloud,典型应用就是一个独立的的复制状态机去管理领导选举和存储配置信息并且在领导人宕机的情况下也要存活下来。比如 Chubby 和 ZooKeeper。
其他资料⌗
下面两个网站有演示Raft算法的交互式动画,做得非常好!